Problem Statement
Standard behavior cloning models often fail in complex manipulation tasks by "averaging" divergent expert trajectories, leading to suboptimal movements.
Our objective: Build a robot capable of identifying handles, synchronizing 7-DOF arm and mobile base movements, and successfully opening cabinet doors in randomized kitchen environments.
System Design & Methodology
1D Convolutional U-Net
Our model utilizes an ActionChunkUNet1D architecture. We implemented Action Chunking with a 16-step prediction horizon and 8-step execution horizon to mitigate the "stuttery" movements typical of standard BC.
Contact-Phase Importance Sampling
Using a WeightedRandomSampler, we prioritized precision during the grasping bottleneck. Training frames within 0.05m of the handle were assigned higher weights, forcing the optimization to focus on successful clamping and initial pulling.
State-Space Augmentation
- • Handle Geometry: 3D coordinates and relative distance to EEF.
- • Temporal Awareness: 50 diffusion steps for denoising.
- • Stall Detection: Logic to resample action chunks if hinge angles remain static.
Quantitative & Qualitative Results
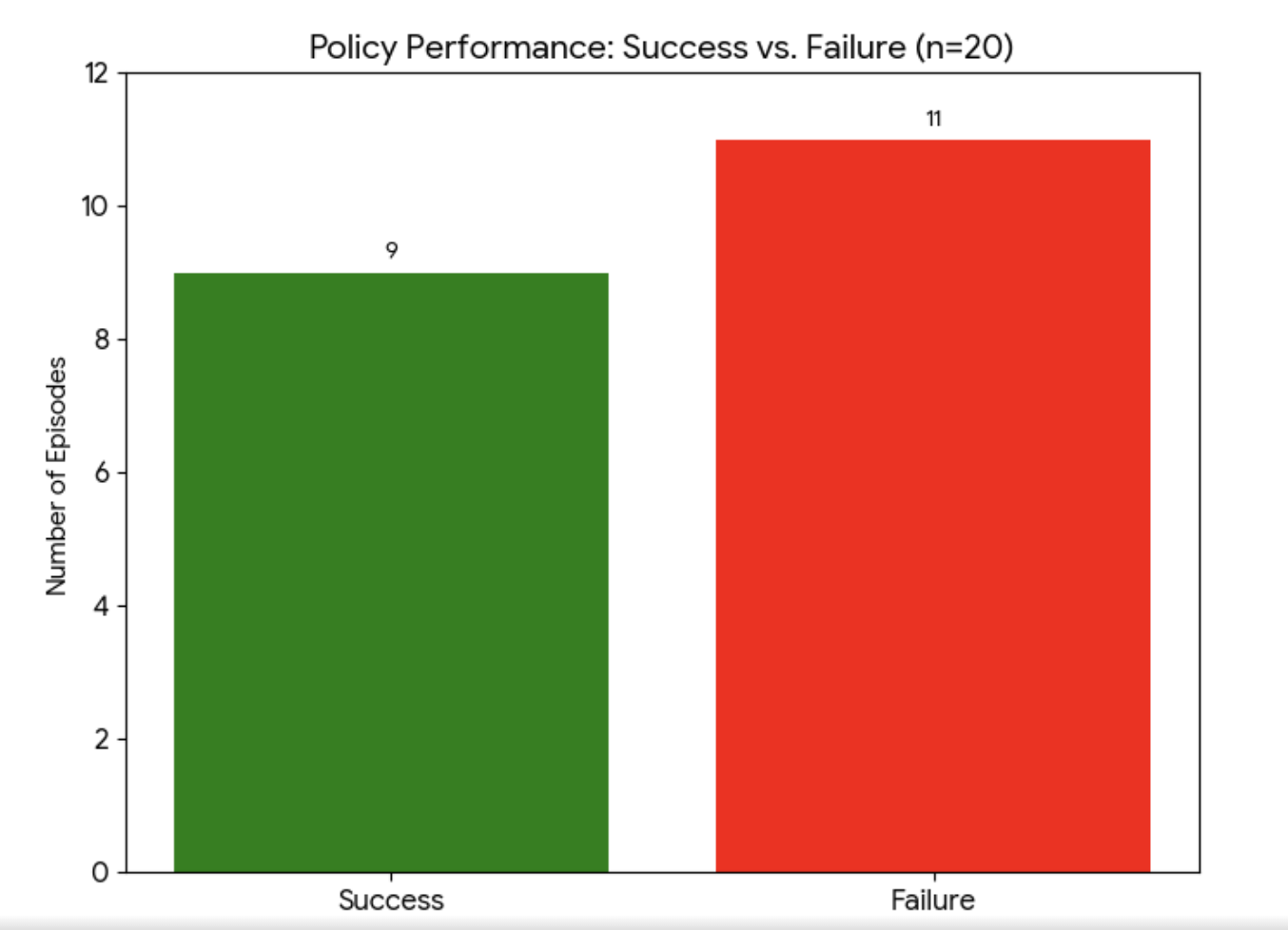
Success vs. Failure Distribution
Steps to Completion (Success Cases)
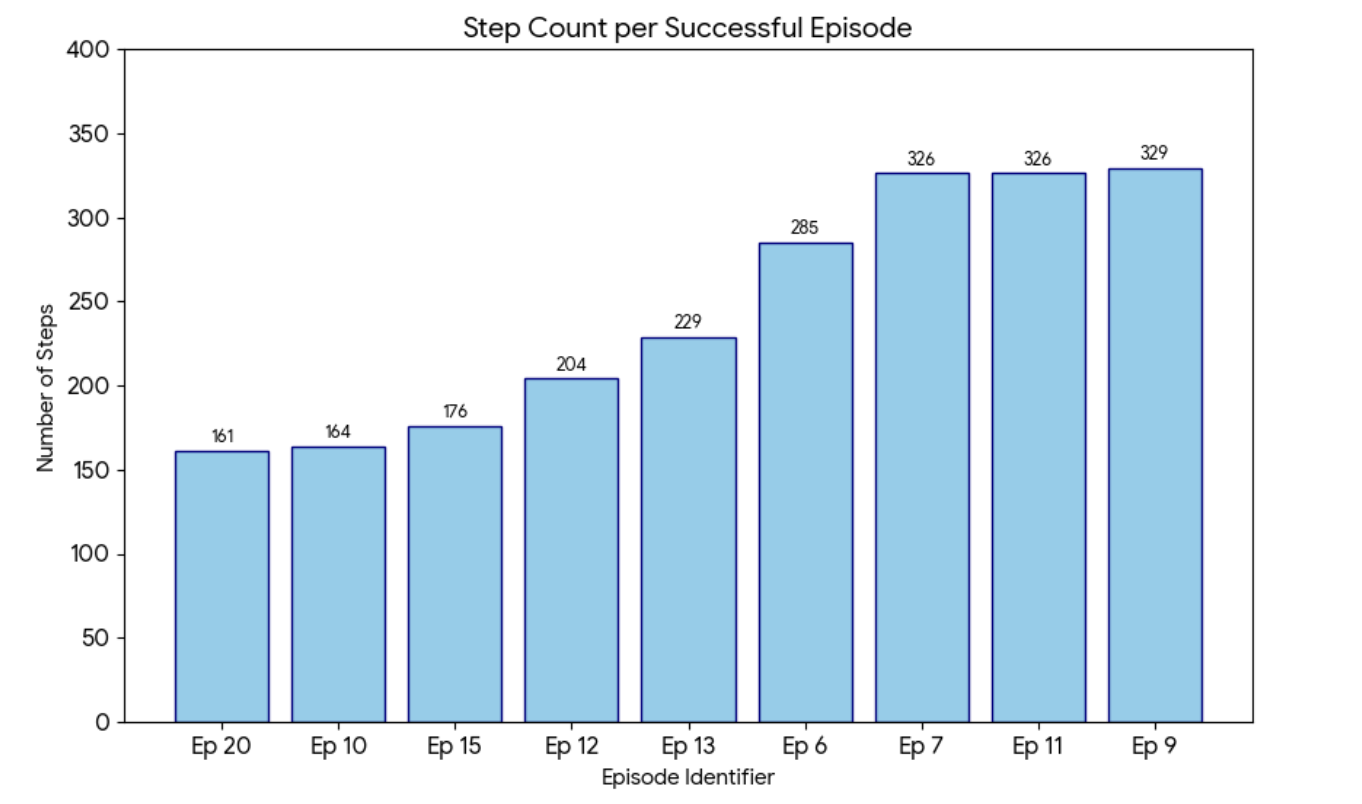
Success defined as max_door_open > 0.90 within 700 steps.
Failure Analysis
Common Failure Modes
- 01. Grasp Slippage: Occurs when the robot reaches the handle but fails to maintain friction lock during high-torque pulling phases (e.g., Test 5 reached 0.81 openness).
- 02. Workspace Singularities: Randomized base initializations occasionally forced the arm into kinematic limits.
Discussion & Future Work
Reachability Maps
Implementing maps to allow the PandaOmron to dynamically reposition its base before initiating a reach, reducing the kinematic strain on the arm.
Vision-Language Models (VLM)
Moving beyond pre-recorded demonstrations toward real-time visual environment understanding for more adaptive movements.